Machine learning for production introducing D ONEs MLOps repository

With this blog post, D ONE introduces “d-one-mlops”, a public repository with a fully functioning end-to-end MLOps training pipeline that runs with Docker Compose. Our goal is to (1) provide you with a MLOps training tool and (2) give you a head start when building your production machine learning (“ML”) pipeline for your own project.
But let’s start from the beginning: we know about ML libraries to build our models, we have been introduced to DevOps for continuous delivery of high quality software… Why do we need MLOps all of a sudden?
The reason is that machine learning brings additional challenges to those encountered in traditional software development. This is because we are dealing with a dynamic component that is at the core of our product — data.
In a ML problem, the mathematical function that determines how the input maps to the output is unknown at first and is only learned from data. When the data changes, we have to go back and retrain our model, or even go a step further, back to the drawing board, where we need to reprocess the training data and restart the search for best model architecture and hyper-parameters.
Dealing with data and models that constantly evolve creates the need for tasks such as:
- Tracking the data to be able to reproduce previous experiments and pipeline runs
- Tracking experiments and models to find the best set-up and ensure the correct model version is in production
- Automate hyper-parameter search to re-tune the model with new data
- Orchestrate the workflows to automate and monitor the complete ML pipeline
With MLOps, the discipline of building and maintaining ML production systems, we apply and automate such ML specific data engineering, data science and software development tasks.
Enough with the theory. As with everything, the best way to learn is by doing. With “d-one-mlops”, we are providing a GitHub repository that includes a complete MLOps training pipeline for a specific use case along with instructions for a Docker-based installation as well as a set of tutorials and exercises aimed at learning MLOps tools and best practices.
So what is the use case?
You receive a dataset with measurement data from wind turbines (see the EDA for more details). Goal is to build a production-like MLOps pipeline around a ML model that nowcasts malfunctions of such wind turbines.
This is what our pipeline looks like:
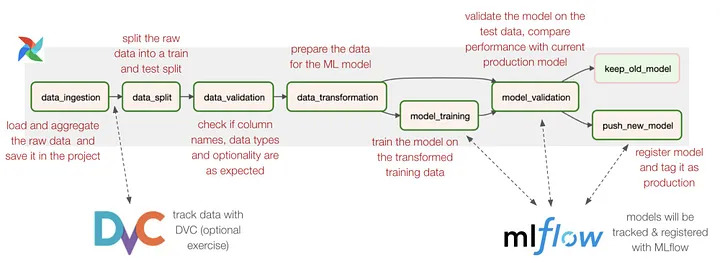
We already built the basic pipeline for you. Following our tutorials and exercises, you will interact with and build onto it. Specifically you will learn how to:
- Track your data with DVC
- Track your experiments and register your models with MLflow
- Orchestrate your MLOps pipeline with Apache Airflow
- Work with these tools to improve your ML models and workflows
Why did we choose these specific tools?
For each problem we picked a tool that (1) is open source, (2) is popular within the open-source community and (3) ideally serves the purpose of our specific task. There are many other tools available (see AI landscape) and when building your own MLOps project you should pick what you are most comfortable with and is ideal for your use case.
Ready to get started? Go ahead and
- Clone the repo and get everything running by follow the readme
- Run the tutorials and exercises by following the handout
- Go through the our slide-deck for more in depth information on the technology stack used
Found a bug or have any questions?
We invite you to contribute. Please report issues directly on GitHub, create pull requests if you have suggestions for improvements, ask questions in the comments section of this article or directly contact us via info@d-one.ai.