A Trip to the LLM Zoo
Dr. Andrei Dmitrenko
The rise of digitization has led to a massive increase in data in white-collar criminal cases. From contracts to meetings, emails to phone calls, everything is meticulously documented. As a result, the need to effectively process all this stored information has become more crucial than ever before. Platforms like Herlock.ai utilize the latest breakthroughs in language modeling, Large Language Models (LLMs), to extract relevant information and offer experts support in legal analysis in an uncomplicated way. While LLMs offer tremendous potential in transforming legal practice, it is important to understand their strengths and limitations. In this article, we will discuss our experience exploring the capabilities of three LLMs: Alpaca, Vicuna, and GPT 3.5.
The models
The concept of Language Modeling dates back to the 1950s, but it wasn’t until the advent of Deep Learning algorithms and big data that LLMs became as powerful and sophisticated as they are today. One major breakthrough in the development of LLMs was the introduction of the GPT (Generative Pre-trained Transformer) architecture by OpenAI in 2018. This architecture allowed for the creation of larger and more complex language models than ever before, culminating in the release of GPT-3 in 2020.
LLaMa was released in 2023 by Meta’s AI team. The initial goal of Meta was to give access to this LLM to the academic research community. Since its release, Meta AI’s LLaMa has become the foundation to all sorts of conversational AI models.
In the same year, researchers at Stanford released Alpaca, an instruction-following LLM based on Meta’s LLaMA. The model is fine-tuned on a dataset of 52,000 instruction-following examples generated from InstructGPT, the model behind ChatGPT. The latest addition to the list is Vicuna, a collaboration between researchers from UC Berkeley, CMU, Stanford, and UC San Diego. Vicuna is trained by fine-tuning a LLaMA base model using approximately 70,000 user-shared conversations gathered from ShareGPT.com, resulting in an enhanced dataset.
Harnessing the power of LLMs
LLMs have proven to be effective tools for improving several features that are already present on Herlock.ai, allowing us to achieve more accurate results. Entity detection, relation and date extraction, as well as content summarization are some examples of the features we are currently exploring to enhance with the power of LLMs.
Validation
Systematic evaluation and comparison of LLMs is not trivial even considering a single well-defined task such as entity detection. One approach is to compile a dataset of testing examples, run the models to collect predictions and calculate the appropriate metrics. However, defining the different types of errors, like false positives and false negatives, is often ambiguous, while the limited amount of data available for testing adds to the challenge.. Having multiple tasks, some of which do not have a definitive answer (e.g., summarization), makes it difficult to objectively compare the performance of LLMs.
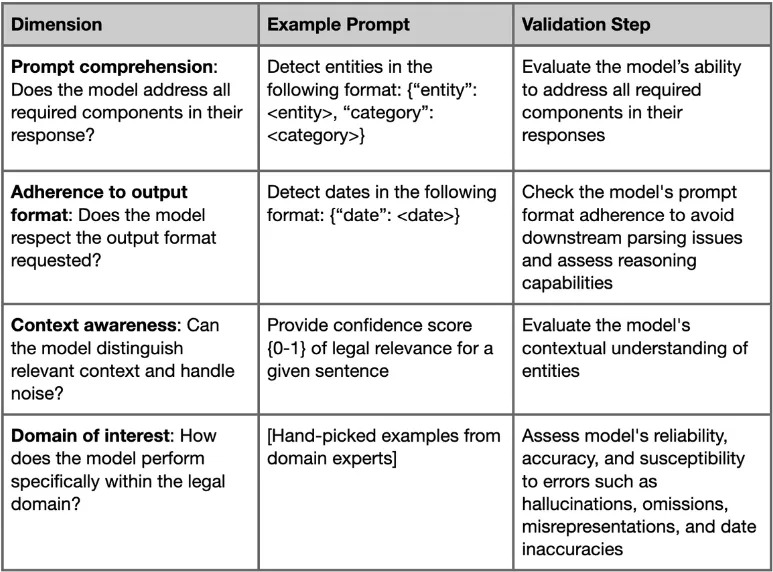
For our experiments, we adopted a pragmatic approach of qualitative assessment that evaluates the models across multiple dimensions. By carefully considering each model’s unique strengths and limitations, we can arrive at informed decisions regarding the most appropriate model for a given task.
- Assess the model’s ability to comprehend and respond to prompts. We employ test prompts ranging from complex, multi-part questions to simpler ones, measuring the LLMs capacity to address all required components in their responses.
- Evaluate the model’s adherence to the specified format in prompts, as failure to respect the formatting can cause issues in downstream output parsing.
- Assess context-awareness by examining the LLM’s ability to discern local relationships within the text and distinguish between relevant context and noise. This assessment includes determining the model’s capacity to identify contextually related words or phrases connected to specific entities (e.g., context related to a specific date entity).
- Evaluate the model’s performance specifically within the legal domain. We challenge the LLMs with multiple tasks, such as summarization or information extraction, and qualitatively evaluate their performance. In this step, we assess the models’ reliability and accuracy, while determining their susceptibility to hallucinations, fact omission or misrepresentation, as well as date inaccuracies. For this, real-world legal texts were used from our in-house database.
Notes:
- Internal legal data were applied only to local models. To test models like GPT that send information through APIs, publicly available legal documents were used instead, to address the privacy concerns.
- When possible, we experimented with the available model parameters, such as temperature and top-k, to examine the model’s behavior and identify the parameter set that best aligns with our task requirements.
Experiments
Entity recognition is the task of identifying named entities such as people, organizations, and locations in text. LLMs are particularly useful for this task as they leverage the context of a sentence to identify the named entities more accurately.

The task of entity recognition in the above example is representative in different ways. First, we observe that Alpaca ignores the specified output format. Second, we find that Vicuna gives explanations for the output despite explicit instructions not to. In our experience, this has been hardly controllable, meaning that multiple prompt engineering attempts to suppress any additional information to the required output failed. Third, LLMs are prone to generating false positives (the case of GPT 3.5). Despite the fact that GPT 3.5 was the only model to identify all organizations and persons correctly, it did output items not belonging to named entities as well.

Another important aspect of practical use of LLMs is the limited consistency of the output. Identical prompts can give drastically different outputs. In the example above, we observed a complete and correct answer from Alpaca on the second attempt, while Vicuna made other types of mistakes compared to its initial output. This highlights the complexity of systematic comparison of LLMs. Noteworthy, GPT 3.5 has been more consistent in our experience.
Date validation serves as a crucial step in minimizing inaccuracies found in extracted sets of dates. To test the models in this task, we provide a prompt where we ask the model to evaluate whether a given string semantically represents a date or date-like object in the context.

We use the Johnny Depp trial proceedings as an example. We chose this sentence because it contains a string with formatting that could lead a model to erroneously identify it as a date. We ask LLMs to evaluate whether it actually represents a date. Alpaca gets the answer wrong and does not follow the requested output format. Vicuna answers correctly and in the requested format.
A critical part of Legal Document Analysis is the Event Context Summarization. For this task we wanted to test the capability of LLMs to extract the relevant, and at times intricate, context tied specifically to a date that we provide. Let’s see an example of this with a sentence from the publicly available Twitter’s complaint against Elon Musk.
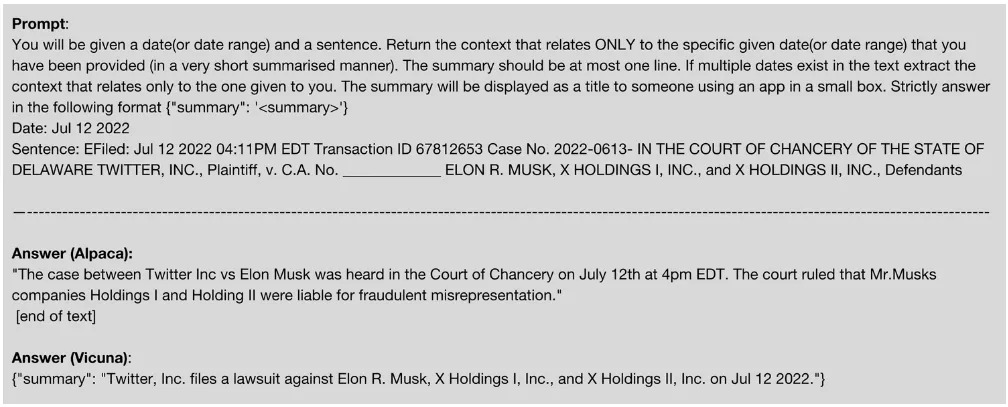
Alpaca is not able to follow the requested response structure. It completely warps the meaning of the sentence that it was given to summarize and invents information This is an example of the undesirable behavior exhibited by LLMs, which has been termed “hallucination”. On the other hand, Vicuna does distill the information from the sentence down to just a few words.
We have also experimented with another task, Legal Relevance Classification. In this scenario, we ask the model to compare the context of a specific date to the abstract meaning of legal relevance and give us its confidence that the context is significant from a legal standpoint. Below, we showcase some examples with prompt and answer combinations of Vicuna and GPT-3.5-turbo.

We observe that both models perform well when presented with clear, noise-free sentences. Our testing reveals that Vicuna struggles to handle sentences containing noise or irrelevant information. Vicuna appears to generate a global semantic representation of the given sentence, so the introduction of noisy information with positive sentiment alters that representation and confuses the model. In contrast, GPT-3.5 seems capable of discerning local relationships within the sentence and maintaining local semantic representations of the context.
During our experimentation process, Databricks released Dolly v2, the first fully open source instruction-following LLM. With some preliminary testing that we conducted, the model’s apparent level of capability is limited. Finally, initial tests with GPT-4 indicate that this latest iteration outperforms even GPT-3.5, the previous state-of-the-art model.
Key insights
- Avoid using very large prompts that ask for a very complex task. On the contrary try to break it down to smaller and simpler prompts that can be executed sequentially. While prompting an LLM try to be very clear and give strict instructions. Ideally, the LLM should make as few decisions on its own as possible in order to minimize unexpected behavior.
- Sometimes history retention can get in the way. For example if the model is configured to retain history it can use information from the previous sentence that it was asked to summarize on the current one.
- LLMs can sometimes give unexpected output for example in their formatting, one should keep this in mind and create fault-tolerant parsing methods for the output of the model.
Challenges for the responsible deployment of LLMs in the legal industry
As promising as the performance of these models is, the deployment of these technologies presents significant challenges, especially regarding data privacy and security. One major concern is the potential exposure of confidential client information to third-party providers. When using LLMs hosted by external providers, legal professionals need to ensure that all confidential data is handled securely and in compliance with data protection laws. This means implementing strict security protocols and ensuring that data is only accessed by authorized personnel. The threat of data breaches or cyber-attacks also cannot be ignored, making it essential to use secure data encryption protocols to protect sensitive client data.
Moreover, there are licensing issues related to the commercial use of most of the models that we have tried. For example, all models that are derived from LLaMA even though open source, are only to be used for research purposes. At the same time many other models such as the ones provided by OpenAI are completely closed source.
Finally, there is a need for the addition of proprietary enterprise knowledge into the models without the need to fine tune each one of them. Currently this is done by storing chunks of documents in vector databases and retrieving the most relevant ones at inference time to provide them as context in the prompt of the model. This however is limited by the context that the model is capable of handling. Research is currently being done that tries to increase the context length to millions of tokens, thereby enabling the incorporation of vast corpora as context.
Outlook
Over the next year, we expect continued progress in scaling up LLMs to even larger sizes, with models reaching trillion parameters or more. It is worth noting that although larger parameter counts are essential for LLMs’ continued progress, there are other avenues for improving their efficacy beyond sheer scale, like refining model architectures, optimization algorithms and adopting more effective strategies for model fine-tuning. These developments suggest that the democratization of LLM technologies is approaching, with performant models potentially becoming available on commodity hardware within the next 6 to 12 months.
Combining LLMs with structured knowledge bases for more systematic knowledge; multitask learning across languages to build models that can operate in multiple languages; generating language that is more coherent, consistent and empathetic over long-form dialogue; and ensuring these systems are fair, unbiased, and respect user privacy, are some of the dimensions in which continued progress is also expected to occur in the near future.
Conclusion
Ultimately, the GPT models demonstrate significantly superior performance compared to the alternatives, while the other models have yet to attain the level of readiness required for deployment. In cases where a local model is necessary, Vicuna emerges as the most promising option, although for research purposes only. However, it is imperative to exercise due diligence and evaluate each model’s capabilities before arriving at a decision regarding its suitability for a particular use case.
At Herlock.ai, we are committed to exploring the latest advancements in LLMs to improve our products and services continually, as we continue to push the boundaries of NLP technology. Our experiments have given us valuable insights into how these models can enhance various NLP features for different use cases. We believe that these models have the potential to revolutionize the field of legal analysis, and we are excited to be part of this transformative journey.