Entity Resolution, the secret sauce to data quality & people centred AI
Entity resolution (ER) is a problem that arises in many information integration scenarios, where two or more sources contain records on the same set of real-world entities. While manually aggregating a few customer ID’s might initially not pose a substantial problem; the problems associated with ER grow equally fast as aggregated data sets and databases expand. As the sheer volume and velocity of data growth burgeon, inference across networks and semantic relationships between entities naturally becomes increasingly complex. An article by Gartner estimates that for each record it takes $1 to verify as it is entered, $10 to cleanse and deduplicate it and $100 if nothing is done, as the ramifications of the mistakes are felt over and over again.
It takes $1 to verify a record as it is entered, $10 to cleanse and deduplicate it and $100 if nothing is done, as the ramifications of the mistakes are felt over and over again.
While ER problems may seem abstract at first they have tangible business consequences. For example, a financial service company may as a result from not implementing ER processes lose customers due to poor service or unwarranted business risks. A manufacturer will miss a unified view over the customer, which prevents a consistent customer experience and cross or up-selling opportunities (find a great overview of use cases, here). Actually, these kind of problems described above arise not only within companies but can affect whole industries. For example, a McKinsey Global Institute report stated that the US healthcare system alone could save $300 billion a year — $1,000 per American — through better integration and analysis of the data produced by everything from clinical trials to health insurance transactions to smart running shoes.
Entity resolution builds a contextual data foundation that enables you to enhance decision making and existing decision making tools
Ideally ER creates a complete and meaningful view of data across the enterprise that reflects real-world people, places, and organisations — and the relationships between them. For example, transforming entity records (normally people or organisations/groups) into a single version of the truth that can be used as input for machine learning or Artificial Intelligence (AI) models involving customer data. Consequently, ER then becomes essential for improving accuracy in predictions. It therefore builds a contextual data foundation that enables an organisation to enhance decision making across the customer lifecycle, uncover hidden risk, and discover new unexpected opportunities.
So what is Entity Resolution exactly?
As mentioned, Entity resolution (ER) is a problem that arises in many information integration scenarios, where two or more sources contain records on the same set of real-world entities. Say, you notice you have duplicates in your address book - an ER task. An organisation calls you about a subscription offer despite already being a customer - an ER task. A customer calls you but seems to be associated with three different customer IDs - an ER task. ER thus deals with the task of disambiguating these kinds of records that correspond to real world entities such as customers or products. Here is another nice way to think about ER:
Entity resolution is about recognising when two observations relate semantically to the same entity, despite [possibly] having been described differently. Conversely, recognising when two observations do not relate to the same entity, despite having been described similarly.
Clearly, if we want to ask questions about all the unique entities in, say, a data lake, we must find a method for producing an annotated version of that dataset such that it contains unique entities. This method will typically involve three primary tasks: deduplication, record linkage and canonicalisation. These provide answers to questions such as: How can we tell two entities apart for sure? What if attributes vary across references? How many entities exist? Which reference do we treat as the main version? How will we manage duplicates?
- Deduplication: eliminate duplicate (or exact) copies of repeated data
- Record linkage: identify records that reference the same entity
- Canonicalisation: unify records or convert data into a standard form
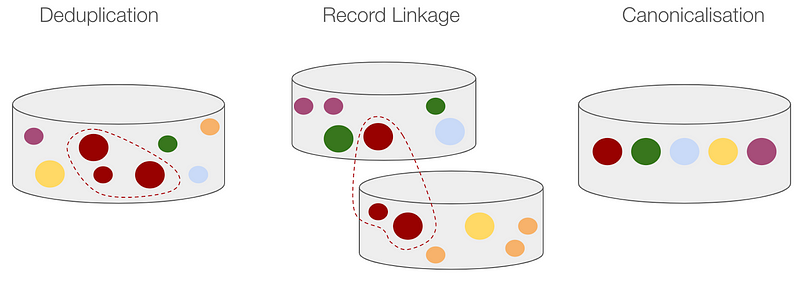
As such, it is worth pointing out that deduplication is an important task in ER and the focus of this article, but as we see above not the only.
Where do duplicates come from?
Unlinked or duplicate records can stem from data quality issues such as trivial typos or empty fields. Take a look at the example below in figure 3. If these ‘un-deduped’ records below were used, a machine learning algorithm would receive five client personas instead of two. Thereby reducing the efficacy of any customer analytics tools built on this dataset. Variation however can also occur for more legitimate reasons. For example, a company may decide to include more information in a record over time resulting in schema variations, names of objects or people may change with time leading to entity variations. Such variations — if, not dealt with — can amount to a substantial barrier in an organisation’s ability to make use of analytics, automate processes or simply keep an overview of its data as a whole.

Further, location may exacerbate this problem. The unfortunate reality with data is that it is often the exhaust of specific applications or processes, never designed to be conjoined with other datasets to inform decision making. As such, datasets containing different facets of information about the same entity are often silo’ed in different places, have different shapes, and/or do not have consistent join keys. This is where ER can be particularly useful, to systematically and periodically integrate disparate data sources and provide a holistic view on entities of interest.
What methods exist to perform ER?
Traditionally, ER has been approached as a similarity problem applying rule-based entity matching methods. Meaning that entity representation, such as table rows, are compared using similarity measurements and applying weights to different characteristics. Examples include Cosine similarity for numbers, Jaccard similarity for strings, Edit or Levenshtein distances for fuzzy string similarity metrics. Such deterministic methods are relatively straight-forward, transparent and fast to implement. They work well in scenarios where a small number of possibilities for differences exist in terms of characteristics.
For example, there are not many ways in which Swiss postcodes can be written so postcode matching is a good use case for rule-based Entity Matching. However, once names and addresses are added to the scope, this approach can become time-consuming and inaccurate as differences increase or new differences emerge regularly. For example, imagine a matching engine for customers of a retailer who plans to expand operations into a new and linguistically different geography. The matching engine will need to be continually updated with new naming and address conventions; forming eventually an unmanageable cathedral of rules.
Traditionally, ER has been approached as a similarity problem applying rule-based entity matching methods. When such deterministic methods are unsuitable to the use case, one can opt for machine learning or deep learning to more automatically learn improved similarity functions.
When such deterministic methods are unsuitable to the use case, one can opt for machine learning or deep learning to more automatically learn improved similarity functions, tailored for the current use case and relying on enough training data in the form of positive and negative examples. This will train a model (i.e. generate matching rules) based upon the input data provided; avoiding the need to manually build matching rules. dedupe, zinggAIor py_entitymatching examples of such solutions. More complex variants may even employ deep learning to reason about entity similarities. Recent examples here include ditto and deepmatcher.
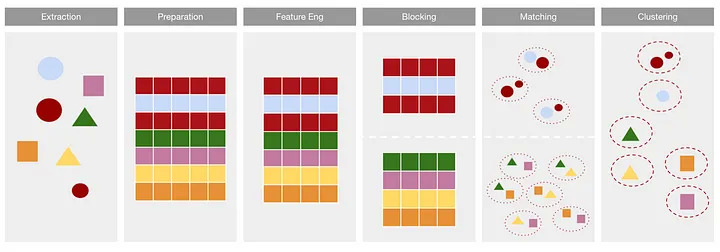
The aforementioned machine learning solutions usually follow a common architecture, illustrated in Figure 4. Once the data sources are identified, data can be extracted and combined into one single format. Then, the data requires some preparation. This step will involve validating and examining the data in order to best normalise the data (see simple example removing some diacritics below). Behind the scenes, the rows of one or more tables are initially processed to extract specific representations (usually vectorised representations). This step is commonly called Feature Engineering and chiefly involves including the characteristics that explain the most variation between entities.
import pandas as pdde_mapping = {'Ü': 'U', 'Ä': 'A', 'Ö': 'O'}
trans_table = ''.join(de_mapping.keys()).maketrans(de_mapping)
df = pd.DataFrame({'name': ['Muller', 'Müller', 'Mueller']})
df['clean_name'] = df['l_name'].str.upper()
df['clean_name_fin'] = df['clean_name'].str.translate(trans_table)
The Blocking step is optional, yet an essential step, because it drastically reduces computational cost in large dataset contexts. For n number of records, there exists n*(n-1)/2 unique pairs. Meaning, whenever the number of records increases 10 times, so does the number of comparisons - yet a 100 times. The blocking process hence removes obvious non-duplicate matches. That is, instead of having every record being compared against every other record, blocking limits the comparison-scape to (ideally) relevant comparisons.
The result of the blocking then forwards groups of duplicate candidates to a matching process where a supervised classification algorithm performs pairwise comparisons within each block group. The matching process results in similar entities being grouped into clusters that can be evaluated based on set criteria, and informs further model development. There are a few tutorials that you might find useful that go through this process step-by-step (see the reference section below).
A framework for setting up an ER engine
In the following, I propose a framework for going about a new ER project. Basically my lessons learnt from a project where I employed dedupe. The latter is a library that uses machine learning to perform deduplication and ER quickly on structured data. As noted, it isn’t the only tool available in Python for performing ER tasks, but it is perhaps one of the few that focuses on ER as its primary task and can perform record linkage across disparate datasets. Another benefit of this approach is that employee knowledge can be harnessed via Active Learning to improve similarity functions, discussed further below in more detail. Further, dedupe scales fairly well (see Rossetti and Bilbro, 2018).
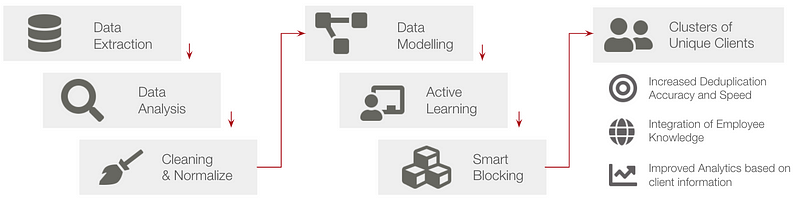
1. Explore and identify the business value
This is a central question that will likely be guided by regulation and added business value. A starting point to evaluate the business value is to examine the current pain points and costs (e.g. additional marketing spend, data cleaning time, …) associated with unresolved entities via a business process mapping. This process could produce a heatmap that highlights affected business areas and the associated costs incurred from duplicates or manual matching. Adding such a business value perspective allows to evaluate the need for a deduplication solution, yet also to prioritise which duplication causes to address once identified later on.
2. Deep dive and prepare the data
In the first phase of the project, a focus should lie on analysing, cleaning and transliterating record fields to have a solid foundation for deduplicating:
- Analysis: at the end of this stage the majority of duplicate causes in a dataset should be identified and should help narrow down a solution space for normalisation activities required in the cleaning and transliterating stages
- Cleaning: obvious variations should be targeted and unified. In the case of addresses, typical variations that require normalisation are casing, diacritics, punctuation, numbers and salutations. It is good to involve domain knowledge in this step in order to understand un/necessary variation specific to the business. For example, in a list of business clients a representative would know what certain abbreviations such as Pvt, Ltd, corp, enterprise, and LLC mean and whether the items are referring to different subsidiaries or not.
- Transliteration: especially when a business operates in different linguistic contexts transliteration will prove extremely helpful. It involves transferring a word from the alphabet of one language to another. To this end, one may detected non-English languages or words by the presence of unicode characters in the strings and use one-to-one mappings for all Latin and say Cyrillic characters. This increases the likelihood for the model to understand that two words or names both represent the same entity.
It is beneficial and constructive to already run a simple deduplication model after each normalisation cycle on the data. This allows to highlight obvious unnecessary variations and further potential for normalising the data as best as possible. As such, this step can be an iterative way to familiarise oneself with the data at hand.
3. Define the setup
In this step, three topics require attention: system requirements, methods and evaluation criteria. Questions that might be guiding in regards to systemrequirements are: how many records needs to be deduplicated? does the tool have to work across different (customer) systems? is real-time deduplication required? In terms of method, selecting a satisfying method will involve considering the concrete ER tasks requirement (see ER tasks above), and which method will best meet those requirements. Finally, it makes sense to upfront discuss evaluation criteria and user acceptance criteria. Here a few examples:
- Measure predictive power via AUC-ROC curve
- Look at the false positive rate and adjust the threshold on duplicate scores
- Create a representative, labelled subsample with the business to cross-verify (e.g. cases that absolutely must be recognised)
4. Include domain expertise
Effective deduplication relies largely on domain expertise. This is for two main reasons: first, because domain experts develop a set of heuristics that enable them to conceptualise what a canonical version of a record should or could look like. Even when they have never seen it in practice. Second, domain experts instinctively recognise which record subfields are most likely to uniquely identify a record; in other words they just know where to look.
With methods that do not involve active learning, this form of knowledge would be extremely useful during the data preparation and featuring engineering. With dedupe specifically and elegantly one can involve the user in labelling an amount of data via a command line interface, and using machine learning on the resulting training data to predict similar or matching records within unseen data.
5. Enable transfer learning
Once the deduplication is completed, it is worthwhile considering ways to optimise further deduplication costs. One obvious way is to address the root causes for duplication in the first place. For example, enhancing business processes could lead to the reduction of future duplicates, which would require matching. Another option is to look into what Teodor (2021) terms transfer learning. This approach entails decoupling the entity representation learning from the similarity learning such that one entity resolution task can be reused in other entity resolution tasks. This approach would seem especially sensible in a similar ER domain.
Sparked your interest?
In this article I tried to provide a primer on Entity Resolution with a focus on deduplication with an overview of methods and tips as to how to go about it. Should you have more questions or needs, feel free to reach out. Contact me here. And follow to stay up to date on similar data topics!