Building a Data Vault using dbtvault with Google BigQuery
Robert YousifThis article is a step by step tutorial implementing dbtvault with Google BigQuery.

Introduction
Making sense of data is crucial for every enterprise. One key enabler to create value from data is the Information Factory. The job of the Information Factory is to turn raw data into knowledge — that is, information humans apply to change the course of their business, hopefully to the better.
There are many technological solutions on the market which allow one to build the Information Factory. Today, we look at BigQuery and dbtvault.
DataMesh and Data Vault
The modern enterprise is a complex organization with many departments and processes. In other words, there are many places where data is created and where data is needed. The traditional approach of handling data — the data warehouse — is transformed and enriched in order to fulfil the requirements of the modern organization. In the DataMesh approach, the data management is centered around data products and agile teams which take the responsibility for the Data Products. This approach ensures that all required know-how is coming together when working with data.
The data modelling which suits this approach well is the Data Vault (developed by Dan Linstedt in 2000).
The key advantages of Data Vault are:
- Extensibility as a key design principle, implemented with the concept of attributes in satellite tables.
- Fast onboarding of developers based on the simple and self-similar modeling approach.
- Highly agile and SAFE friendly with change isolation due to functional separation of the data elements (hubs, satellites & links) which enables parallel loading.
- Audit friendly via the insert-only paradigm (provides full history on everything).
- One place for business logic (from raw Data Vault to business Data Vault), ensuring a clean separation between raw & interpreted data.
dbt & dbtvault
dbt is an open source Data Building Tool that facilitates transformation operations using select statements. dbt projects are compiled in a separate runtime environment (local desktop, VM, container etc) and then executed on a target data database. This makes it easier for developing teams to collaborate, test, document and version control the transformations.
dbtvault is a dbt package that extends dbt to build a Data Vault. dbtvault generates your Data Vault ETL code based on your metadata. The compiled SQL statements are sent to the target database where they will run and create hubs, links and satellites as views/tables.
The current dbtvault release only supports the snowflake database. The great dev team is busy finalizing the BigQuery module, however, the code base is already functional on BigQuery for hubs, satellites and links with some minor changes.
dbtvault with BigQuery tutorial using the dbt cli
This tutorial will not focus on Data Vault modelling but rather on how to use dbt and dbtvault together with BigQuery which is currently not officially supported.
This tutorial guides you through the following steps:
- Set up the local python environment
- Install dbt
- Install dbtvault for BigQuery
- Load bike sales sample data into the database using dbt seeds
- Build the staging layer
- Build the raw data vault
Prerequisites:
- GCP account with a BigQuery instance.
- Python with pip installed on your local machine
- Basic sql, dbt and Data Vault knowledge
Setting up the environment
First we need to set up our python environment. Create a new folder which will be the root folder of your project and change the path.
mkdir bg_datavault_tutorialcd bg_datavault_tutorial
Create a virtual environment and activate it.
python -m venv venvsource venv/scripts/activate #For windows using bash
Install dbt & dbtvault
Install dbt.
pip install dbt
To ensure that dbt is installed run the following command:
dbt --version
And you should see the installed version (0.21.0 in my case).
Now we are ready to take the next step and dwell into the world of dbt, and more specifically dbtvault.
Setting up a dbt project
Let’s start with creating a new dbt project.
dbt init bq_datavault_tutorial
Change your path to the newly created project folder and open it in your favorite IDE tool, for me that is VS code. You should see a folder structure like this:
Now dbt needs to establish a connection to a database, the project will be compiled on your desktop but the heavy lifting has to be done on your target database. In order to manage these settings we need to find the profiles.yml file where we set up the connection to our BigQuery instance.
dbt debug --config-dir
There are different methods to authenticate with BigQuery.
BigQuery connection with keyfile/service account file:
Before we test the connection we have to configure the profile inside the dbt_project.yml file which you will find in the root folder of the dbt project. This should match the name of the configured profile, in our case bq_datavault_tutorial.
To test the connection run the following command:
dbt debug
A dbt project is set up with a working connection to BigQuery.
The Quoted Part below is not necessary anymore with the newer releases of dbt-vault. (Jump to step “Load the data using dbt seeds”)
Now we have to download and install the development branch of the open source project dbtvault. The development branch is used as BigQuery is currently not supported in the official main release. A minor change needs to be made as well to enable the creation of hubs as there was a small bug in the official develop branch.
To simplify things, I have forked the dbtvault project and created a new branch that we can use to install the library. In the new branch called develop_unnested, I have moved the project to the root folder so that we can point to the library directly from the dbt packages file.
In the root folder of your project, create a new file called packages.yml. In this file, paste the following:
Then install the packages with the following command:
dbt deps
You should see a new folder called dbt_modules in the root folder of your project.
Load the data using dbt seeds
Before we start building the Data Vault we need to ingest mock data, to do this we will use the dbt seed command which can load local csv files into the database.
In this example we will use the SAP Bikes Sales sample data.
Download the SalesOrderItems.csv and Products.csv and place them inside the data folder in your dbt project.
Run the seeds command:
dbt seed
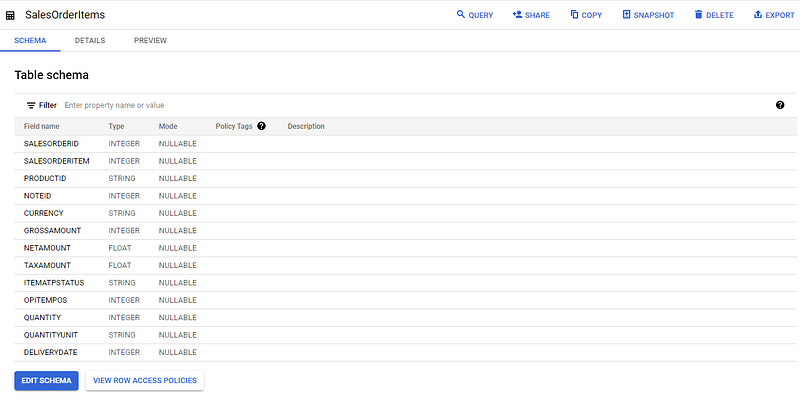
Now you should see two tables inside BigQuery under the name SalesOrderItems and Products.
Build the raw Data Vault
Now that we have the raw data inside our database staging layer, we want to create the hashed staging layer with the help of the dbtvault macro function called stage.
Create a new folder inside the models folder called stage, in this folder create a new file with the name stg_products.sql and insert the following code. The filename determines the table names in BigQuery, in our case the table will be called “stg_products”.
This will create new hashed columns based on the Products table and store the new view in bigquery with the name stg_products.
Let us do the same with the SalesOrderItems table, create a new file in the models/stage folder and call it stg_salesorderitems.sql with the following code:
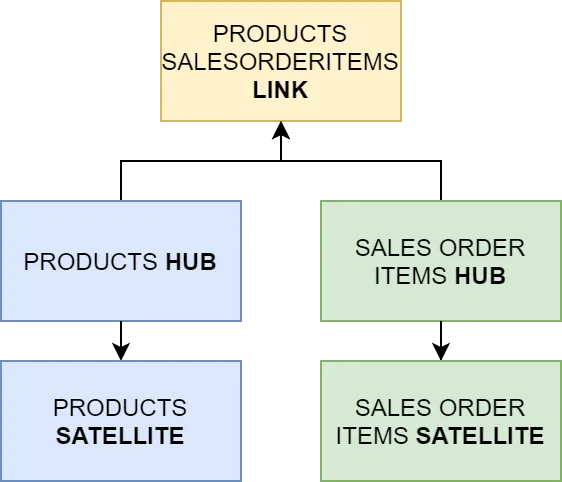
The different hash keys are later used to generate relationships between different tables. In our example this would be the PRODUCT_PK, SALESORDER_PK and the LINK_PRODUCT_SALESORDER_PK.
Let us move on to create the Hubs, Links and Satellites. Create a new folder inside models called vault, in here create three new folders hubs, links and satellites. The models folder should look like this:
As we have two different data sources we will also create two different hubs, one per source. We use the data we prepared in the staging layer to ensure that we use the same data and keys in the hubs, links and satellites.
In the hubs folder create two new scripts and make use of the “dbtvault.hub” macro provided by dbtVault. This macro creates the sql statement needed to build the hubs for us.
hub_products.sql:
hub_salesorderitems:
In the links folder create a new file called link_product_salesorderitem.sql:
Here we only source the stg_salesorderitems and use the LINK_PRODUCT_SALESORDER_PK as our primary key and SALESORDER_PK, PRODUCT_PK as foreign keys. This link is used when we want to query data from both sources at the same time.
In the satellites folder create two new files
sat_product_details.sql:
sat_salesorder_details.sql:
The two satellites contain the actual information (given by src_payload), which we later can use to analyze our data.
Now that we have all the scripts in place, let’s run the whole project.
You should see two satellites, two hubs and one link. The database structure in BigQuery should look like this:
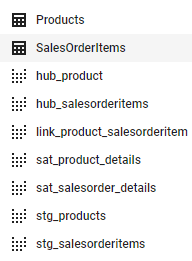
Congratulations, you have created a Data Vault using dbtvault on BigQuery.
The whole project is also available on github.
Conclusion
Data Vault is an excellent data modelling style providing a metadata-driven approach where dbt and dbtvault will handle the logic. Making it very easy to build the Data Vault, both as initial load and as incremental load.
dbtvault for BigQuery is still under development and with tiny changes in the source code of dbtvault, it is now possible to create satellites, links and hubs on BigQuery using dbtvault — with that said, expect further changes before the official release.
Big thanks to the dbt and dbtvault team. Hope you enjoyed this tutorial. For more on BigQuery and Data Vault, check out our other posts and stay tuned for more tutorials around dbtvault.